Deine Content Marketing Strategie basiert auf der Unternehmensstrategie. Außerdem fließt die Marketing Strategie und das generelle Selbstverständnis des Unternehmens ein. Denn eure Inhalte müssen die Persönlichkeit des Unternehmens widerspiegeln.
Die Strategie entwickelst du gemeinsam mit deiner Content Marketing Agentur.
Der erste Bestandteil der Content Marketing Strategie ist eure Zielgruppe. Wenn diese nicht bereits klar in der Marketing Strategie festgelegt ist, wird sie für die Content Strategie neu definiert. Wenn du dich im Content Marketing nur auf einen Kanal konzentrierst, kann die Zielgruppe entsprechend eingegrenzt werden.
Neben der Zielgruppe wird die Art und der Umfang der Maßnahmen festgelegt. Hierzu beantwortest du mit deiner Content Marketing Agentur zum Beispiel folgende Fragen. Viele davon beziehen sich auf die Website, da sie häufig den Mittelpunkt des Content Marketings bildet.
- Auf welchen Kanälen ist die Zielgruppe am meisten unterwegs?
- Wie ist die Website aufgebaut, welche Content Möglichkeiten gibt es?
- Welche Inhalte gibt es bereits?
- Welche Content Elemente eignen sich für die Website?
- Wie wichtig ist das Employer Branding?
- Soll es Social Media Kanäle geben?





")
")




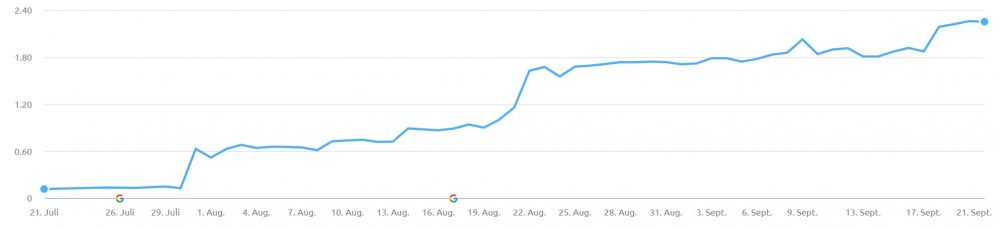
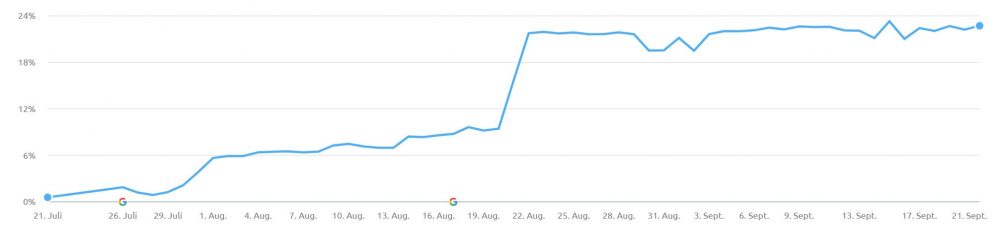













Content Marketing verbessert das Markenbewusstsein: Die Marke wirkt 10% vertrauter, das Image 14% positiver. Zudem wird sie um 14% häufiger weiterempfohlen und dadurch bekannter.
Studie 2015 mit 5.153 Teilnehmern